太平洋在线官网博彩平台游戏策略_详解数据存储的六种可选时期

 亚新电子游戏
亚新电子游戏
本文转载自微信公众号「数仓宝贝库」,作家Saurabh。转载本文请考虑数仓宝贝库公众号。
热数据需要在内存中存储和处理,因此相宜用缓存或内存数据库(如Redis或SAP Hana)。AWS提供了ElastiCache管事,可生成托管的Redis或Memcached环境。NoSQL数据库是面向高速但小范围记载(举例,用户会话信息或物联网数据)的想象遴荐。NoSQL数据库关于履行经管也很灵验,不错存储数据目次。
1结构化数据存储结构化数据存储仍是存在了几十年,是东谈主们最熟谙的数据存储时期。大多数事务型数据库(如Oracle、MySQL、SQL Server和PostgreSQL)都是行式数据库,因为要处理来自软件应用尺度的频繁数据写入。企业平凡将事务型数据库同期用于报表,在这种情况下,需要频繁读取数据,但数据写入频率要低得多。跟着数据读取的需求越来越强,有更多的改进干预了结构化数据存储的查询畛域,比如列式文献步地的改进,它有助于提高数据读取性能,满足分析需求。
基于行的步地将数据以行的步地存储在文献中。基于行的写入步地是将数据写入磁盘的最快步地,但它不一定能最快地读取,因为你必须跳过许多不考虑的数据。基于列的步地将统统的列值悉数存储在文献中。这么会带来更好的压缩效劳,因为调换的数据类型当今被归为一组。平凡,它还能提供更好的读取性能,因为你不错跳过不需要的列。
咱们来看结构化数据存储的常见遴荐。举例,你需要从订单表中查询某个月的销售总和,但该表有50列。在基于行的架构中,查询时会扫描悉数表的50个列,但在列式架构中,查询时只会扫描订单销售列,因而提高了数据查询性能。咱们再来详备先容关系型数据库,要点先容事务数据和数据仓库处理数据分析的需求。
(1)关系型数据库
RDBMS相比相宜在线事务处理(OLTP)应用。流行的关系型数据库有Oracle、MSSQL、MariaDB、PostgreSQL等。其中一些传统数据库仍是存在了几十年。许多应用,包括电子商务、银行业务和货仓预订,都是由关系型数据库扶助的。关系型数据库十分擅所长理表之间需要复杂统一查询的事务数据。从事务数据的需求来看,关系型数据库应该坚握原子性、一致性、斥逐性、握久性原则,具体如下:
原子性:事务将从新到尾十足推行,一朝出现作假,悉数事务将会回滚。 一致性:一朝事务完成,统统的数据都要提交到数据库中。 斥逐性:条目多个事务能在斥逐的情况下同期开动,互不侵略。 握久性:在职何中断(如鸠合或电源故障)的情况下,事务应该草率收复到终末已知的状况。平凡情况下,关系型数据库的数据会被转存到数据仓库中,用于报表和团员。
(2)数据仓库
数据仓库更相宜在线分析处理(OLAP)应用。数据仓库提供了对海量结构化数据的快速团员功能。固然这些时期(如Amazon Redshift、Netezza和Teradata)旨在快速推行复杂的团员查询,但它们并莫得针对宽广并发写入进行过优化。是以,数据需要分批加载,使得仓库无法在热数据上提供及时瞻念察。
当代数据仓库使用列式存储来进步查询性能,举例Amazon Redshift、Snowflake和Google Big Query。成绩于列式存储,这些数据仓库提供了十分快的查询速率,提高了I/O效劳。除此除外,Amazon Redshift等数据仓库系统还通过在多个节点上并行查询以及大范围并行处理(MPP)来提高查询性能。
据透露,此次军援还将包括榴弹火炮以及美军淘汰的设备、迫击炮、侦查无人机和2800万发小型武器弹药等。“黄蜂”侦查无人机是主要用于情报收集的纳米级无人机。
实践中,单位行贿案件较多,与个人行贿相比法定刑相差悬殊。一些行贿人以单位名义行贿,规避处罚,导致案件处理不平衡,惩处力度不足。为此,草案将单位行贿罪刑罚由原来最高判处五年有期徒刑的一档刑罚,修改为两档刑罚:“三年以下有期徒刑或者拘役,并处罚金”和“三年以上十年以下有期徒刑,并处罚金”。
数据仓库是中央存储库,不错存储来自一个或多个数据库的蓄积数据。它们存储刻下和历史数据,用于创建业务数据的分析讲演。固然,数据仓库聚拢存储来自多个系统的数据,但它们不行被视为数据湖。数据仓库只可处理结构化的关系型数据,而数据湖则不错同期处理结构化的关系型数据和非结构化的数据,如JSON、日记和CSV数据。
体验感受皇冠信用登录网址Amazon Redshift等数据仓库搞定有计议不错处理PB级的数据,并提供解耦的揣摸和存储功能,以检朴资本。除了列式存储外,Redshift还使用数据编码、数据分散和区域映射来提高查询性能。相比传统的基于行的数据仓库搞定有计议包括Netezza、Teradata和Greenplum。
2NoSQL数据库NoSQL数据库(如Dynamo DB、Cassandra和Mongo DB)不错搞定在关系型数据库中平凡遭遇的伸缩和性能挑战。顾名念念义,NoSQL暗意非关系型数据库。NoSQL数据库储存的数据莫得明确结构机制结合不同表中的数据(莫得结合、外键,也不具备范式)。
NoSQL期骗了多种数据模子,包括列式、键值、搜索、文档和图模子。NoSQL数据库提供可伸缩的性能、具有高可用性和韧性。NoSQL平凡莫得严格的数据库模式,欧博app下载每札记载都不错有恣意数目的列(属性),这意味着某一排不错有4列,而团结个表中的另一排不错有10列。分区键用于检索包含考虑属性的值或文档。NoSQL数据库是高度分散式的,不错复制。NoSQL数据库十分耐用,高可用的同期不会出现性能问题。
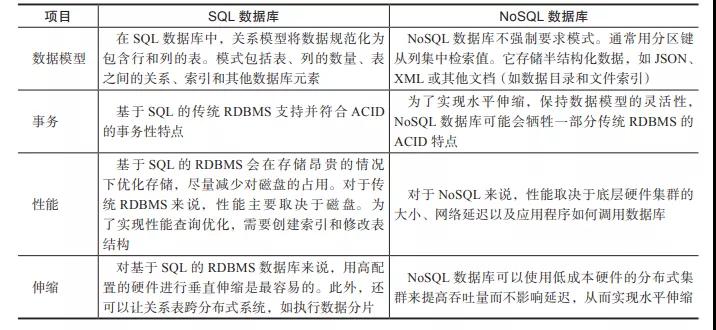
太平洋在线官网SQL数据库仍是存在了几十年,大多数东谈主可能仍是十分熟谙关系型数据库。咱们来看SQL数据库和NoSQL数据库之间的一些要紧区别(见表1)。
表1 SQL数据库和NoSQL数据库的区别
笔据数据特质,市面上有多样类别的NoSQL数据存储来搞定特定的问题。咱们来看NoSQL数据库的类型。
3NoSQL数据库类型NoSQL数据库的主要类型如下:
列式数据库:Apache Cassandra和Apache HBase是流行的列式数据库。列式数据存储有助于在查询数据时扫描某一列,而不是扫描整行。如若物品表有10列100万行,而你想查询库存中某一物品的数目,那么列式数据库只会将查询应用于物品数目列,不需要扫描悉数表。 文档数据库:最流行的文档数据库有MongoDB、Couchbase、MarkLogic、Dynamo DB和Cassandra。不错使用文档数据库来存储JSON和XML步地的半结构化数据。 图数据库:流行的图数据库包括Amazon Neptune、JanusGraph、TinkerPop、Neo4j、OrientDB、GraphDB和Spark上的GraphX。图数据库存储过火和过火之间的说合(称为边)。图不错竖立在关系型和非关系型数据库上。 内存式键值存储:最流行的内存式键值存储是Redis和Memcached。它们将数据存储在内存中,用于数据读取频率高的场景。应用尺度的查询当先会转到内存数据库,如若数据在缓存中可用,则不会冲击主数据库。内存数据库很相宜存储用户会话信息,这些数据会导致复杂的查询和频繁的恳求数据,如用户府上。NoSQL有许多用例,但要竖立数据搜索管事,需要对所稀有据竖立索引。
4搜索数据存储Elasticsearch是大数据场景(如点击流和日记分析)最受接待的搜索引擎之一。搜索引擎能很好地扶助对具有恣意数目的属性(包括字符串令牌)的温数据进行临时查询。Elasticsearch十分流行。一般的二进制或对象存储适用于非结构化、不可索引和其他莫得专科用具能剖析其步地的数据。
Amazon Elasticsearch Service经管Elasticsearch集群,并提供API拜访。它还提供了Kibana当作可视化用具,对Elasticsearch集群中的存储的索引数据进行搜索。AWS经管集群的容量、伸缩和补丁,省去了运维支出。日记搜索和分析是常见的大数据应用场景,Elasticsearch不错匡助你分析来自网站、管事器、物联网传感器的日记数据。Elasticsearch被宽广的行业应用使用,如银行、游戏、营销、应用监控、告白时期、欺骗检测、推选和物联网等。
5非结构化数据存储当你有非结构化数据存储的需求时,Hadoop似乎是一个好意思满的遴荐,因为它是可推广、可伸缩的,况且十分活泼。它不错开动在耗尽级开发上,领有庞大的用具生态,况且开动起来似乎很合算。Hadoop收受主节点和子节点模式,数据分散在多个子节点,由主节点互助功课,对数据进行查询运算。Hadoop系统依托于大范围并行处理(MPP),这使得它不错快速地对多样类型的数据进行查询,不管是结构化数据还短长结构化数据。
在创建Hadoop集群时,从管事器上创建的每个子节点都会附带一个称为腹地Hadoop分散式文献系统(HDFS)的磁盘存储块。你不错使用常见的处理框架(如Hive、Ping和Spark)对存储数据进行查询。关联词,腹地磁盘上的数据只在考虑实例的生命期内握久化。
如若使用Hadoop的存储层(即HDFS)来存储数据,那么存储与揣摸将耦合在悉数。增多存储空间意味着必须增多更多的机器,这也会提高揣摸才调。为了取得最大的活泼性和最好资本效益,需要将揣摸和存储分开,并将两者孤独伸缩。总的来说,对象存储更相宜数据湖,以经济高效的步地存储多样数据。基于云揣摸的数据湖在对象存储的扶助下,不错活泼地将揣摸和存储解耦。
皇冠 博彩 网址 6数据湖数据湖是结构化和非结构化数据的聚拢存储库。数据湖正在成为在聚拢存储中存储和分析宽广数据的一种流行步地。它按原样存储数据,使用开源文献步地来终了径直分析。由于数据不错按刻下步地原样存储,因此不需要将数据调节为预界说的模式,从而提高了数据吸收的速率。如图1所示,数据湖是企业中所稀有据的单一着实源流。
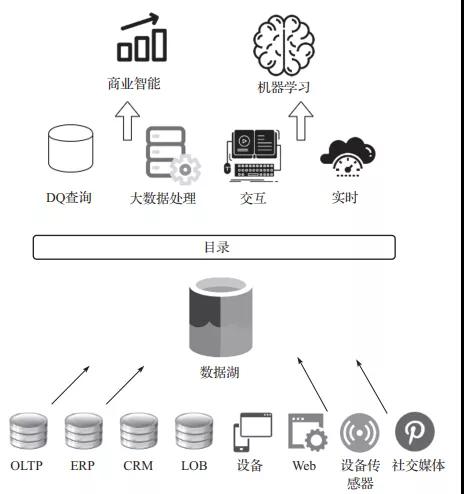
图1 数据湖的对象存储
数据湖的刚正如下:
从多样源流吸收数据:数据湖不错让你在一个聚拢的位置存储和分析来自多样源流(如关系型、非关系型数据库以及流)的数据,以产生单一的着实源流。它解答了一些问题,举例,为什么数据分散在多个场所?单一着实源流在那里?
皇冠体育赔率采集并高效存储数据:数据湖不错吸收任何类型的数据,包括半结构化和非结构化数据,不需要任何模式。这就回话了怎样从多样源流、多样步地的数据中快速吸收数据,并高效地进行大范围存储的问题。
2020年7月非法出境缅甸。2021年9月24日自缅甸经边境投案自首,实行隔离医学观察。9月26日新冠病毒核酸检测阳性,转运至定点医院隔离诊治。结合流行病学史、临床表现实验室检测结果,诊断新冠肺炎确诊病例(普通型,缅甸输入)。皇冠hg86a

跟着产生的数据量束缚推广:数据湖允许你将存储层和揣摸层分开,对每个组件分手伸缩。这就回话了怎样跟着产生的数据量进行伸缩的问题。
将分析要领应用于不同源流的数据:通过数据湖,你不错在读取时细则数据模式,并对从不同资源网罗的数据创建聚拢的数据目次。这使你草率随时、快速地对数据进行分析。这回话了是否能将多种分析和处理框架应用于调换的数据的问题。
博彩平台游戏策略你需要为数据湖提供一个能无穷伸缩的数据存储搞定有计议。将处理和存储解耦会带来巨大的刚正,包括草率使用多样用具处理和分析调换的数据。固然这可能需要一个稀奇的步地将数据加载到对应用具中,但使用Amazon S3当作中央数据存储比传统存储有计议有更多的刚正。
数据湖还有其他刚正。它能让你的架构永不外时。假定12个月后,可能会有你想要使用的新时期。因为数据仍是存在于数据湖,你不错以最小的支出将这种新时期插入使命经由中。通过在大数据处理活水线中构建模块化系统,将AWS S3等通用对象存储当作骨干,当特定模块不再适用或有更好的用具时,不错自由地替换。
皇冠体育比分网亚新电子游戏
本文摘编自《搞定有计议架构师修王人之谈》,经出书方授权发布。(ISBN:9787111694441)转载请保留著作出处。